
About Me
I am a Machine Learning Engineer at Red Hat, where I work on vLLM inference optimization. My current focus is on prefill-decode disaggregation and hybrid model serving, enabling efficient deployment of large-scale LLMs across distributed GPU clusters. I received my M.S. from Cornell Tech and my B.S. in Computer Science (CS) and Electrical and Computer Engineering (ECE) from Cornell University with summa cum laude.
Previously, my research explored optimization for diffusion language models, recommendation systems, and model quantization.
I am broadly interested in ML systems optimization, distributed computing, and efficient inference for large-scale AI. During my time at Cornell, I was fortunate to collaborate with Prof. Zhiru Zhang, Prof. Udit Gupta, Prof. Mohamed Abdelfattah, and Prof. Jae-sun Seo.
Research
Diffusion language models enable parallel token generation and bidirectional context but suffer from slow inference due to iterative denoising, making them impractical for long context reasoning compared to autoregressive models.
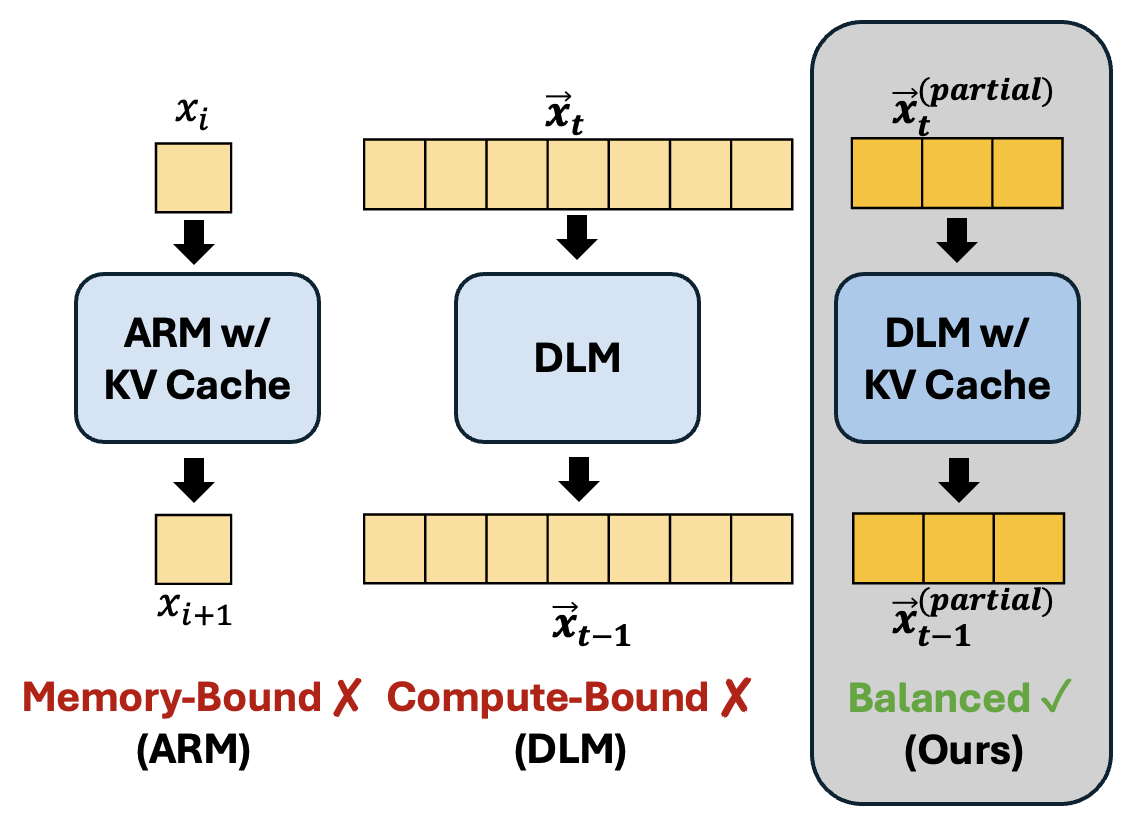
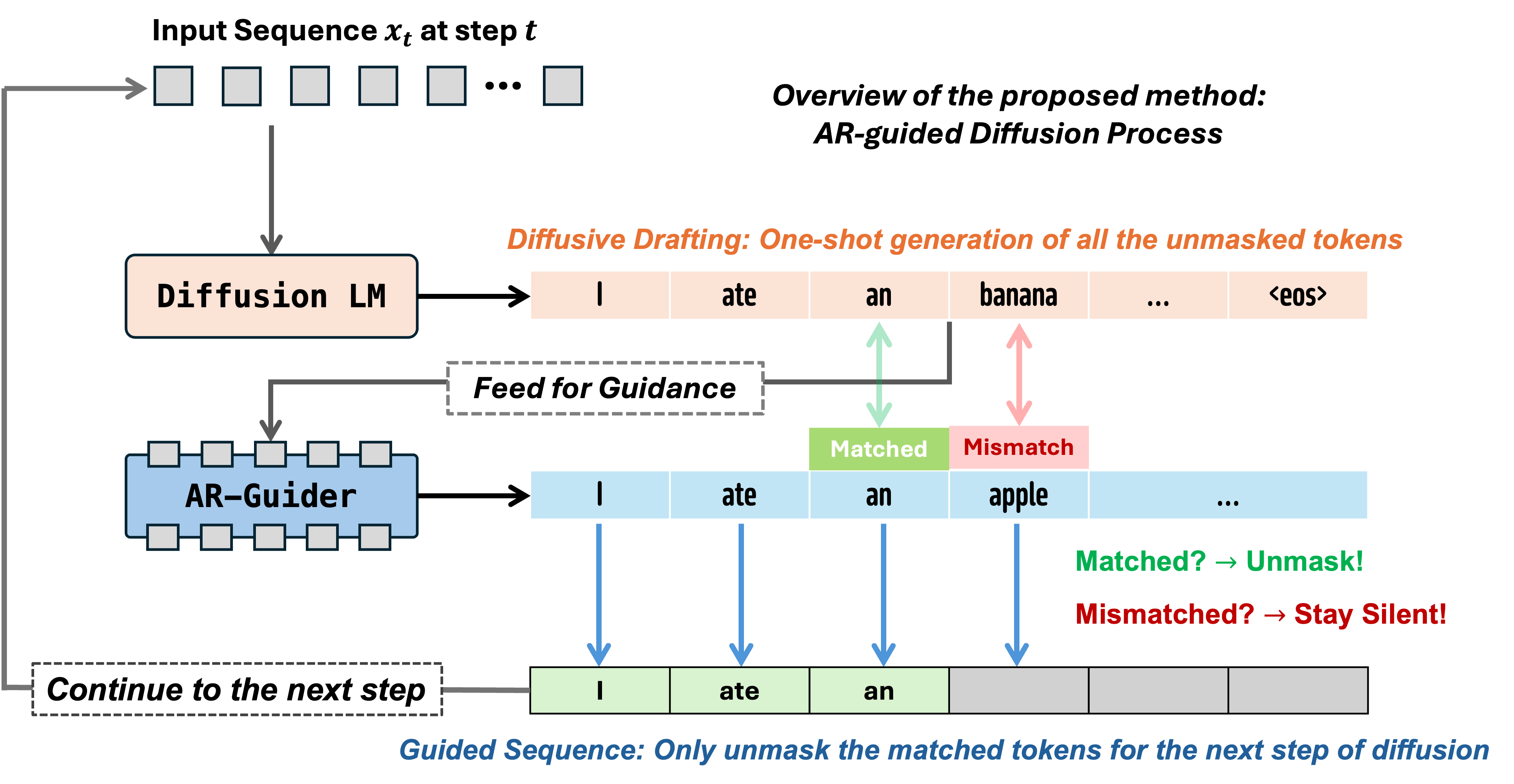
This work introduces FreeCache and Guided Diffusion, two training-free techniques for accelerating diffusion inference. FreeCache reuses stable key-value projections across steps, and Guided Diffusion employs a lightweight autoregressive model to guide token unmasking, reducing the number of iterations while preserving coherence.
Together these methods achieve up to 34× end-to-end speedup with negligible accuracy loss, making diffusion models as efficient as autoregressive baselines and enabling their deployment in real-world applications.
FreeCache
GuidedDiffusion
Beyond the Accelerator: A Full-Stack HW/SW Co-Design Analysis for Recommendation System Inference [Paper]
Modern recommendation systems execute multi-stage pipelines at massive scale, but most optimization efforts target only the deep neural network ranking stage, leaving major bottlenecks in feature fetching, approximate nearest neighbor search, and orchestration.
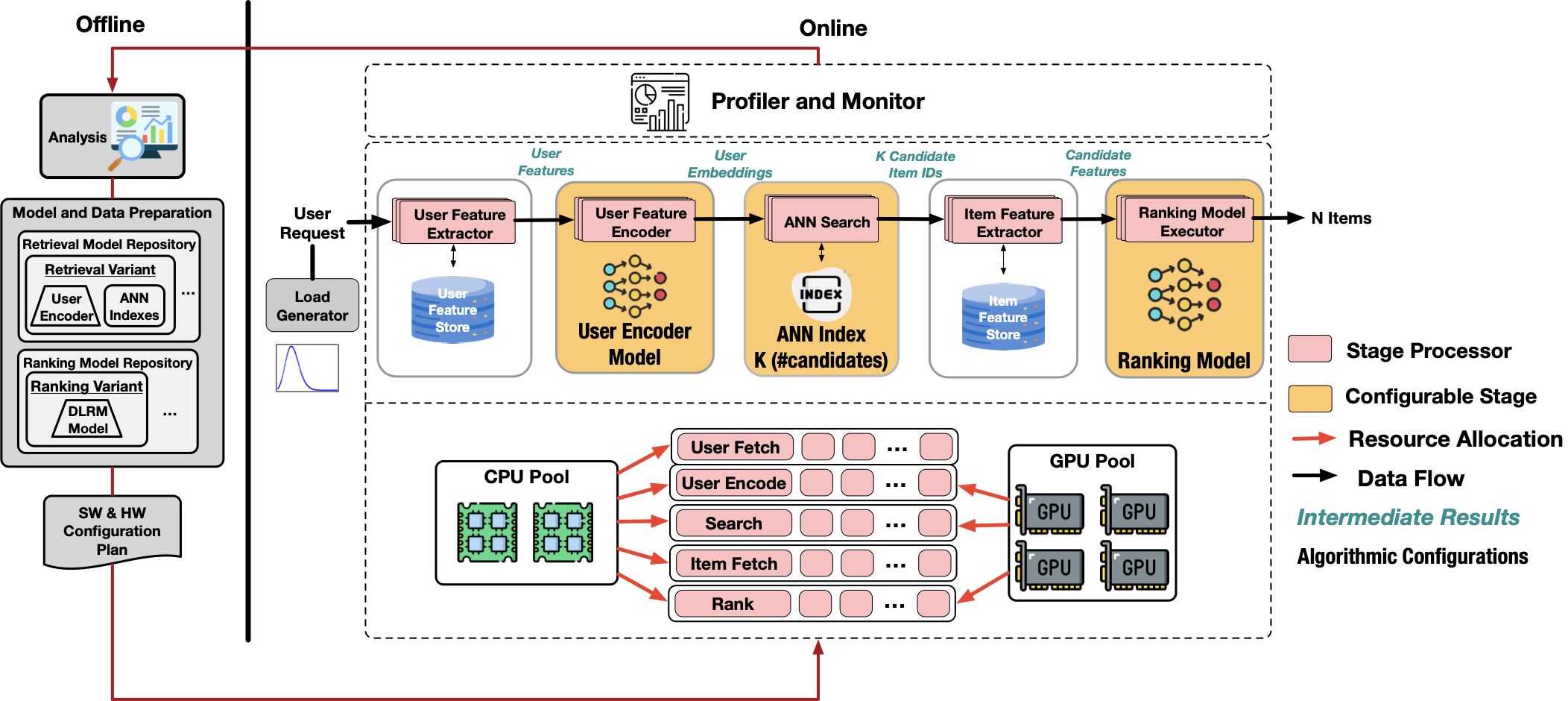
To address this gap, ReCoOpt is introduced as a modular framework that enables systematic hardware and software co-design of end-to-end recommendation inference. The framework profiles and tunes retrieval, feature fetching, and ranking across heterogeneous platforms to explore balanced pipeline configurations.
Using MovieLens datasets, ReCoOpt demonstrates that holistic co-design can improve hit rate by 0.05 under a fixed latency budget, double throughput, or reduce latency by 40%, showing that balanced hardware and software optimization is essential for scalable recommendation engines.
OverQ: Overwrite Quantization for Outlier-Aware CNN Acceleration [Paper]
Low precision quantization reduces the cost of deep neural networks but suffers from rare outliers in activations that degrade accuracy. Existing fixes require retraining or expensive outlier hardware.
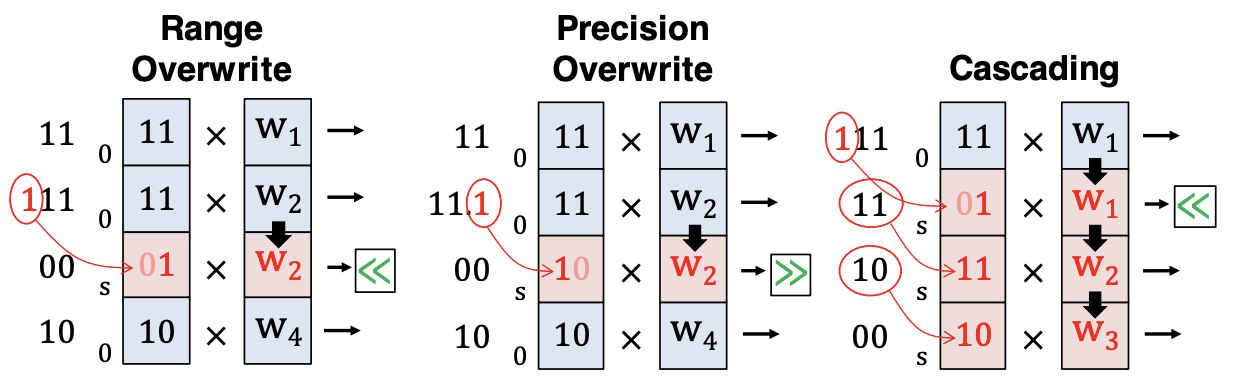
OverQ introduces overwrite quantization, which lets outliers reuse nearby zeros to gain extra range or precision. A simple cascading mechanism expands coverage, and the design fits efficiently into systolic array accelerators.
With modest overhead, OverQ handles over 90% of outliers, improving ImageNet accuracy by up to 5% at 4 bits while adding only about 10% area per processing element.
Teaching
- Course Development: MLSys Teaching Frameworks (Cornell ECE 5545). Led development of PyTorch frameworks for speech recognition model training, fine-tuning, quantization, and deployment.
- Teaching Assistant: CS 1110 Introduction to Computing; CS 4/5780 Introduction to Machine Learning; CS 4/5410 Operating Systems; ECE 5755 Modern Computer Systems and Architecture.